こんにちは!Ryoku(@ryoku_dev)です。
私は大量の商品データをGoogle Spreadsheetに書き出すリサーチをしています。
ただ、こういったアプローチに否定的な意見もあります。優柔不断な自分ですが、

転売であれ直取であれOEMであれ、リサーチにおいて、商品データをリストに書き出す以外に道はないです
と確信しているので、その辺の理由をポジショントーク的な雰囲気もいとわず伝えたいと思います。
※リサーチは意味が広い言葉なので、ここでは「ネット上ですでに販売されている商品を調べる」ことに限定して商品リサーチという言葉を使うことにします
一般的な商品リサーチ
「大量のASINを集めて、MWS APIやKeepa APIなどを使って商品データを取得し、Excel、Spreadsheet、その他リストビューのツールに書き出す」
これはAmazonのケースですが、こんなアプローチからリサーチをする人は私を含め大勢いると思います。
この記事で言いたいことは「リストに書き出した方がいいことが沢山あるよ」なんですが、比較対象をちゃんと決めないといけないので、「一般的なリサーチ」というものを考えます。
「商品リサーチにツールは使わない!」という人の中でも、Amazonの商品ページを見て「商品画像がかっこいいね」「いい機能ついてるね」だけで判断する人は少ないと思います。やっぱり現在のランキングなり過去のランキング変動なりを見て「売れているか」は知りたいわけです。効率よくデータを見るためにブラウザのプラグイン類は使いますよね。
そうするとリサーチで知りたい情報はどんなアプローチでも変わらなさそうです。あとは、商品を選ぶ時に元々のWebページを見ていくかどうか、つまり商品に辿り着くまでの手段の違いがアプローチの違いになりそうです。
よって「リストに書き出すリサーチ」に対して、「一般的なリサーチ」とはブラウザのプラグインを使いながら元々のWebページ上で商品を見ていくリサーチ、であるとさせていただきます。
じゃあ、この2つのアプローチを比較してやろうといった時に、商品リサーチについての共通的な枠組みがいります。
商品リサーチの枠組み
商品リサーチの手順を超ざっくり抽象化すると、こんな感じの枠組みで捉えられます。
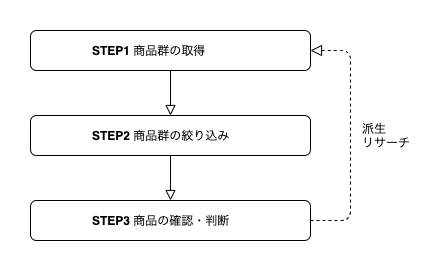
STEP1では、今回のリサーチ対象となる商品群を取得します。セラーリサーチであればそのセラーの出品商品、カテゴリリサーチであればカテゴリの出品商品一覧、キーワードリサーチであれば検索結果です。
STEP2では、取得した商品群全てを見るわけにはいかないので対象の絞り込みをします。ソートして上位100件見るとか、Keepaのグラフをチラ見するとか、目新しい商品画像だけ見るとか。
STEP3では、実際に商品情報を確認して、仕入れ候補とするかを判断します。仕入れ可能なのかを確認し、利益や販売数を計算します。もちろん、そもそも自分が販売してよいかも確認します。また、ここから同ブランド、同ジャンル、関連商品などの派生リサーチもします。
STEP2とSTEP3は密に関連しています。STEP2が絞り過ぎで漏れが多ければリサーチの結果として得るものが少なくなります。STEP2が絞らなすぎで不正解が多ければSTEP3の負荷が上がります。
至極当たり前のことを書いてしまいましたが、一般的なリサーチ、つまり元々のWebページでこのステップを行うイメージはすぐに湧くのではないでしょうか。
リストに書き出すリサーチの利点
次はリストに書き出すリサーチの場合です。商品IDの他に商品名、価格、出品者数などの情報を含め、まとめてリストに書き出します。Amazonの商品の場合だとこんな感じです。
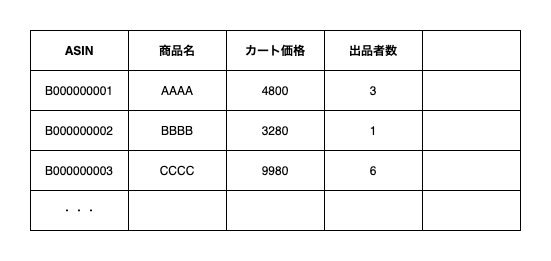
ExcelやSpreadsheetそのままのイメージです。他のツールの場合も、ツールによって操作、表現、処理速度に差はありますが本質は同じです(もちろん、操作や表現に差があるために実現できる機能に差は出ます)。
ではその本質とは何か?
リストなので一覧性が高いこともありますがそれは副次的なもので、大事なのは判断のための指標を有した商品データを蓄積・取り出しできることです。
ブラウザに表示した商品情報はその場限りで流れて消えていきますが、商品データとしてリストに書き出しておけば、必要なものをシステムが判定して取り出したり、いらないものだけ消したり、最新の情報を取り直したりできるということです。
もちろん、リサーチ結果を蓄積することは手でリスト管理してもできますが、だったら初めからなんらかのツールを使って取得・蓄積をした方がずっと効率がいいはずです。
先の枠組みに当てはめた時、リストに書き出すことで次の3つの利点を生み出すことができます。
- 一度取得した商品は取得しなくていい (STEP1)
- 自動でスクリーニングできる (STEP2)
- 一度蓄積した商品は何度でもリサーチできる (STEP3)
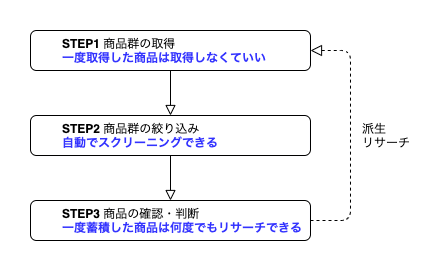
次に、リストに書き出すアプローチの3つの利点についてそれぞれ説明します!
利点1. 一度取得した商品は取得しなくていい
これは他の記事でも繰り返し書いていますが、「後で買うかも」とストックした商品だけでなく、「扱うことはないな」と除外した商品も蓄積しておくことで、常に進出の商品だけを取得することができます。
例えばセラーリサーチをしていて、同じセラーの商品を後日取得した場合には、新しく追加された商品だけを取得できてしまいます。
利点2. 自動でスクリーニングできる
価格・出品者数・販売個数などのデータが取得できるとすると、これらを指標としてリストの絞り込みができます。
例えば「販売個数」は仕入れ判断のための超重要な指標です。「リスト作成時に販売個数が月3個以下のものは除外する」というルールを設定しておけば、自動で商品のスクリーニングができます。数値判定だけでなく、NGワードを設定しておき、商品タイトルや説明と照合して除外することもできますね。
指標の選び方と閾値の大小で、
「漏れは許容して、効率優先で狭めに絞るのか」
「不正解は許容して、取りこぼしがないように広めに絞るのか」
は変わります。これは一見ツールを使わないリサーチのところで書いたことと同じに見えますが、何となく絞って結果そうなるのではなく、自分で設定して結果をコントロールできるのは大きな違いです!
狭め、広め、どちらの絞り方にも好みによりますが、私の好みは断然狭めです。例えばAmazonの中だけでも自分が把握しきれないほどの商品があり、売れ出したもの、売れなくなったものも次々と変わっていきます。それらを網羅することにあまり意味はありません。せっかくツールを使うのであれば広く網をかけて、狭く絞る方が、その特性を活かせると思います。
利点3. 一度蓄積した商品は何度でもリサーチできる
販売価格、仕入価格、販売個数、出品数などの指標の値は変動します。なので、リサーチ時点では仕入れ基準を完全に満たしていなくとも、ストックしておき商品のデータを定期的に更新することで、仕入れ基準を満たすタイミングを捕まえることができます。
一度商品をストックしてしまえば、STEP1とSTEP2をすっ飛ばしてSTEP3の仕入判断だけを実行できるということです。
転売の場合に限りますが、一番大きく変動しやすいのは価格です。仕入価格、販売価格は(ある意味、時間差で連動して)どちらも動きます。なので他の指標は満たしているのに価格差だけがない、だけど履歴を見ると価格が変わっている、という場合はストックするのがおすすめです。
似たようなやり方に、KeepaやCamel Camel Camelの価格アラートに登録するものがあります。もちろん有効なやり方ではありますが、アラートで分かるのは仕入価格の指標が満たされたということだけなので、この後で他の指標のチェックは必要になってしまいます。
最終的な仕入れ判断は同じ
と、ここまでリストに書き出すリサーチの利点を主張してきましたが、最初の方で述べたように「一般的なリサーチ」と比較をしているのは商品に辿り着くまでのやり方の違いでした。
最終的には商品ページを開いて、きちんと商品の内容を理解して、ツールで取得した指標通りなのか、仕入商品と合致しているカタログなのか、自分が販売していい商品なのか、など多角的に確認をする必要があります。
始めたての頃、Spreadsheetに取得した情報だけみて、販売ページを開かずに仕入れをしたことがありました。今考えると恐ろしい・・・。
過去にちゃんと確認をして仕入れをし、再度仕入れる場合でも、商品ページは一応確認した方がいいです。最初に仕入れた時は「並行輸入品」と表記してあったページが、リピートしようとした時には「正規輸入品」に変わっていたことがありました。なんでそんな変更が可能なのかはいまだに謎ですが、チェックしてよかったと胸をなでおろした瞬間でした。
まとめ
今回の記事のタイトルは「リサーチをExcelやSpreadsheet上で行う3つの利点」ですが、内容は多少一般化して「リストに書き出すリサーチの利点」を説明しました。抽象的なレベルの話が多かったので分かりにくくなってしまったかもしれません。
改めて! 記事を書く前に一番お伝えしたいと思っていたことは、沢山優れたブラウザのプラグインがある中で、わざわざ「ExcelやSpreadsheetに商品の情報を書き出す」ことにどんな意味があるのか、ということでした。
結論としては今回紹介した以下の3つの利点が得られるということなんですが、それは、「ExcelやSpreadsheetに商品の情報を書き出す」というプリミティブな動きが、データの自在な蓄積・取り出しを可能しているからでした。
- 一度取得した商品は取得しなくていい
- 自動でスクリーニングできる
- 一度蓄積した商品は何度でもリサーチできる
ちなみに、前に公開したKeepa APIのお試しリサーチツール「SHEET for Keepa」も機能は限定的ですが、今回説明した特性を備えています。見方によっては単に商品情報をSpreadsheetに書き出すだけのツールですが、下記の関連記事の中で説明した利用方法を知ってもらうともう少し価値が生まれてくるはずです。

理屈っぽい記事が続きましたが、次回は私が今使っているリサーチツールの具体的なご紹介をしたいと思います。
最後まで読んでいただきありがとうございました!


